|
Bill Zheng I'm an incoming PhD student at UT Austin studying computer science, where my research will be supported by an NSF Graduate Research Fellowship. Currently, I am a research scientist intern at NVIDIA's General Embodied Agent Research (GEAR) group. I completed my undergraduate degree in EECS at UC Berkeley, where I am grateful to be advised by Professor Sergey Levine at Robotics, AI, and Learning Lab. I am also fortunate to work with Professor Kuan Fang and Professor Benjamin Eysenbach. I'm broadly interested in the intersection between machine learning and robotics, where I aim to scale up reinforcement learning for downstream applications in real-world robot learning problems. |

|
|
[May. 2026] Started my internship at NVIDIA GEAR! [Apr. 2026] I will be attending ICLR in Rio de Janeiro! Excited to present our new work on multistep quasimetric learning! [Apr. 2026] I'm selected for NSF GRFP! |
 |
Multistep Quasimetric Learning for Scalable Goal-conditioned Reinforcement Learning
Bill Zheng, Vivek Myers, Benjamin Eysenbach, Sergey Levine ICLR 2026 paper / website / code We demonstrate the effectiveness of using quasimetric distance representations in horizon-generalization by performing multistep backups. This allows us to scale up compositional tasks to real-world, pixel-based tasks using offline GCRL. |
|
|
Offline Goal-Conditioned Reinforcement Learning with Quasimetric Representations
Vivek Myers, Bill Zheng, Benjamin Eysenbach, Sergey Levine NeurIPS 2025 paper / website / code / arXiv Using a combination of Monte-Carlo contrastive learning and necessary invariances, we can find the optimal goal-reaching Q function with quasimetric representations in offline goal-conditioned reinforcement learning (GCRL). |
|
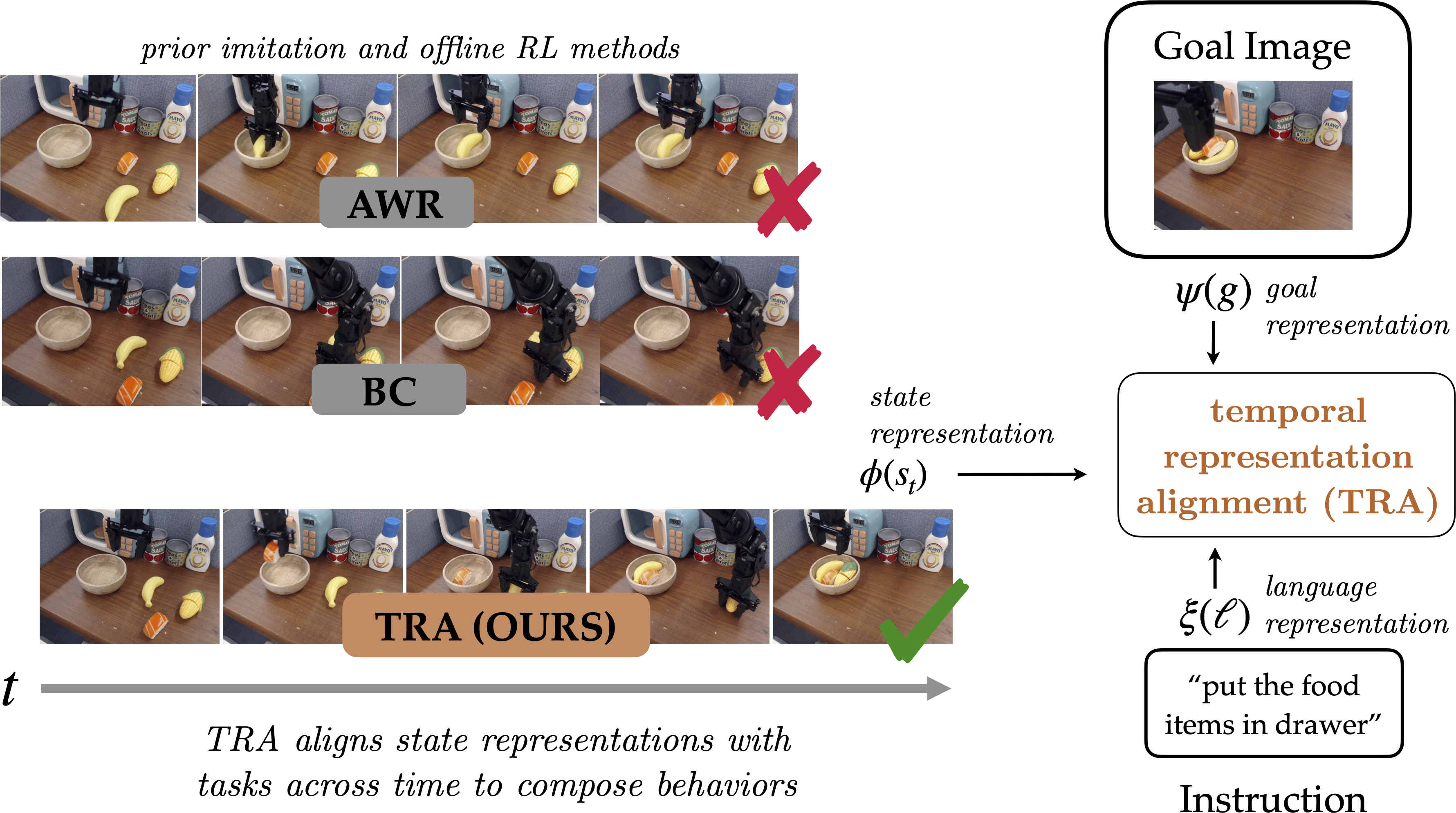
Temporal Representation Alignment: Successor Features Enable Emergent Compositionality in Robot Instruction Following
Vivek Myers*, Bill Zheng*, Anca Dragan, Kuan Fang, Sergey Levine NeurIPS 2025 Learning Efficient Abstractions for Planning Workshop, CoRL 2024 paper / website / code / arXiv We propose Temporal Representation Alignment (TRA), a policy learning method that utilizes the quasimetric property of temporal distances, and observe emergent capabilities in following compositional instructions when trained on a real world robot dataset. |

|
Policy Adaptation via Language Optimization: Decomposing Tasks for Few-Shot Imitation
Vivek Myers*, Bill Zheng*, Oier Mees, Sergey Levine†, Kuan Fang† CoRL 2024 project page / twitter / code / arXiv We propose an effective and sample-efficient nonparametric adaptation method for learning new language-conditioned robotic manipulation tasks by searching for the best language decomposition and executing these instructions in inference.
|


|
Course Coordinator, EECS16B (Designing Information Devices and Systems II), Computer Science Mentors |
MiscellaneousI grew up in Orange County, California, so my collection of favorite sports teams are peculiar (Go Warriors, 49ers, Angels, and Ducks!). In my (somewhat) free time, I like to enjoy the following:
|
|
Website template used from Jon Barron. |